情境描述:
之前在我的电脑上装了Portal for ArcGIS和ArcGIS Server,并且共用一个ArcGIS Web Adaptor,
后来Server组的同事建议Portal for ArcGIS和ArcGIS Server分别用一个ArcGIS Web Adaptor,
于是我先将Portal for ArcGIS和ArcGIS Server解除联合,然后卸载掉ArcGIS Web Adaptor,
接着安装了两个ArcGIS Web Adaptor,注册server的命名为server,注册portal的命名为arcgis。
安装之后,分别注册Portal for ArcGIS和ArcGIS Server,接着联合,成功!
ArcGIS中使用字段计算器创建日期序列字段
当我们有一些空间数据,想通过动画的形式展示,可以在ArcGIS中的时间滑块工具实现。如果图层要开启时间属性,得有日期类型字段,所以首先需要创建相应字段。
如果我们对要素的先后顺序没有要求,可以通过字段计算器快速生成自增型日期,实际之前我已经写过字段自增的博文ArcGIS中使用字段计算器生成随机数和自增数
这里我是在ArcGIS Pro中实现,(可以看到ArcGIS Pro中不在支持VB语法,只支持python了)
使用ModelBuilder批量处理和命名问题解决
ArcGIS中使用字段计算器生成随机数和自增数
当我们使用ArcGIS,在编辑字段或者有某种数据处理需求时,想要新建个字段生成一列随机数或者自增序列数,
下面是实现得过程和代码:
首先新建个字段,字段类型是整型或者浮点或者双精度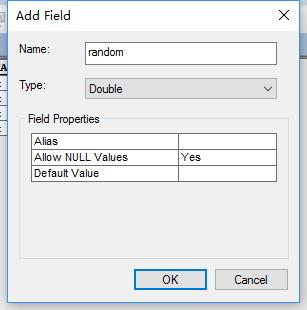
(1)生成随机数
长城符号制作---图层叠加 vs 制图表达
主要有两种方法
1、图层叠加:在符号编辑器中通过三个图层符号叠加作出来,参数设置如下: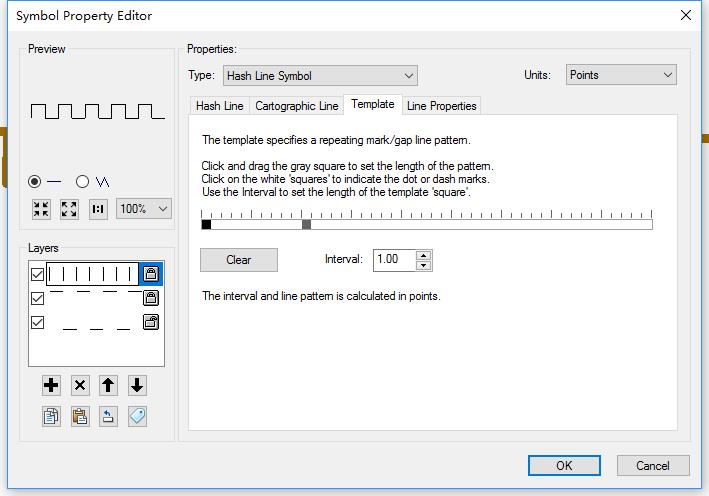
在ArcGIS以弹窗形式挂接图片
1、首先右击图层打开属性表,添加一个文本型的字段,长度改为150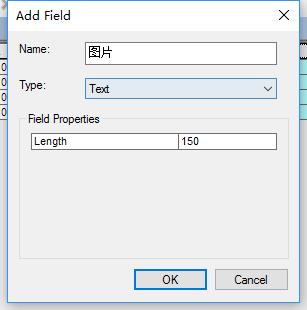
ArcGIS ModelBuilder的工作空间(workspace)设置问题
今天和同事调试了一个用户发来的ModelBuilder,咋一看,模型做得还好呀,每个工具的调用和参数设置都很有逻辑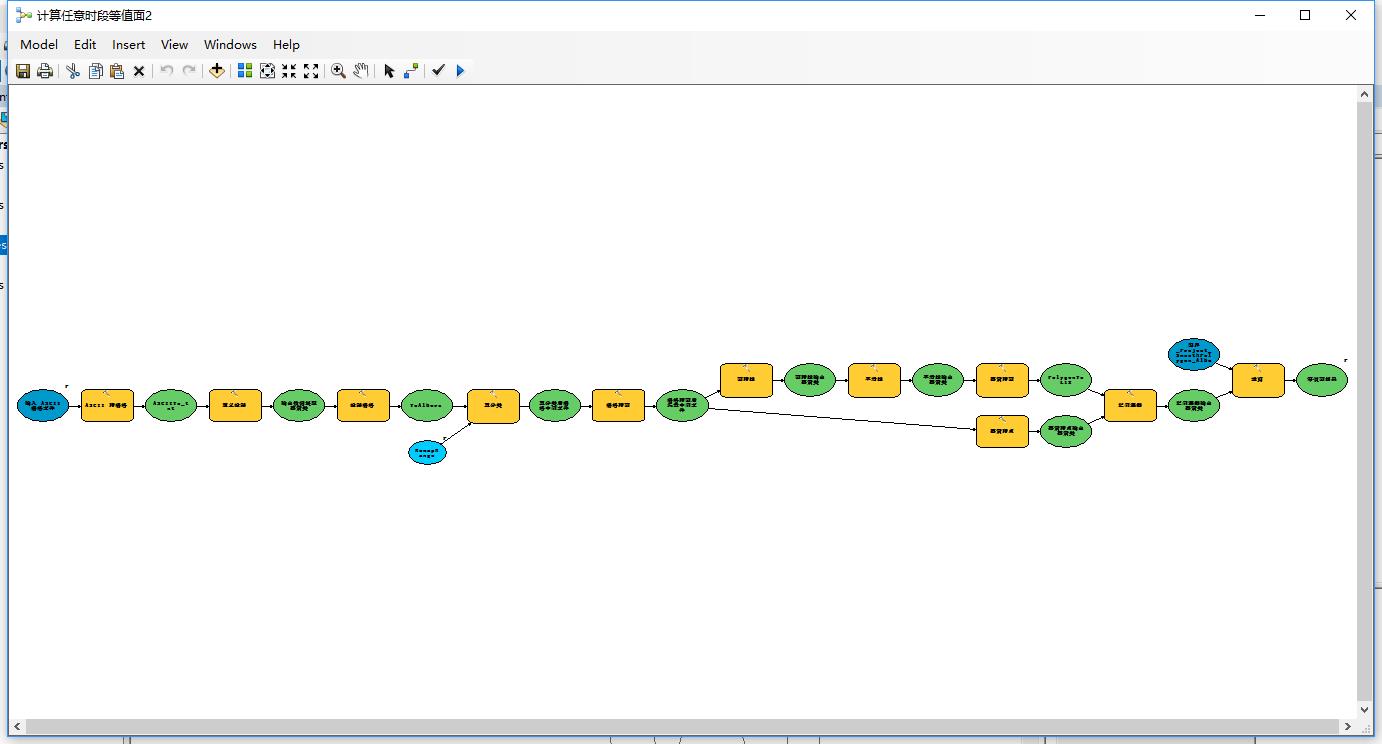
但是一点击运行后,
欲戴其冠,必承其重---谈谈ArcGIS制图表达
很早的时候,ArcGIS中就增加了制图表达的功能,只是用的人不多,所以一直不为大多数人所知。本来ArcGIS的基本标注已经满足大部分的出图需求,制图表达如同没有开封的美酒,一直等待去开启,但是任何东西都要有个度,如果酒喝多了也不好,影像做事效率。
ArcGIS专题图边框花纹制作
之前在呼市培训碰到有个学员问到怎么设置ArcGIS专题图的边框花纹,一直觉得这个花哨,没必要去设计,上周末去地坛公园玩,看到墙上的画都有花纹边框,感觉很美观
