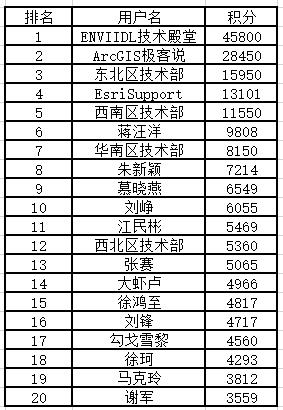
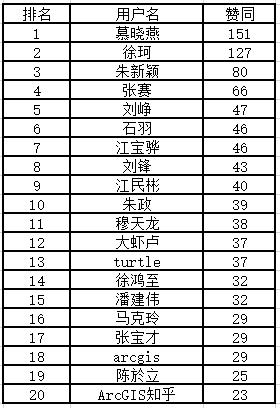
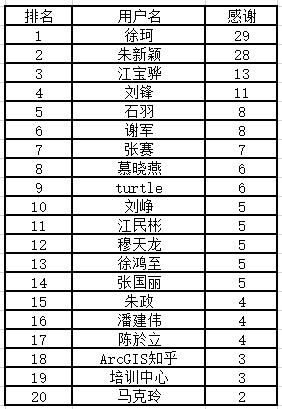
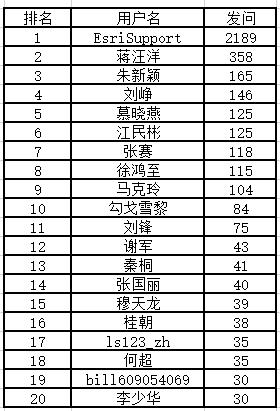
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
|
__author__ = 'jiang'
import urllib2
import BeautifulSoup
import re
import datetime
starttime = datetime.datetime.now()
file = open('C://Users//Esri//Desktop//arcgiazhihu.txt', 'a')
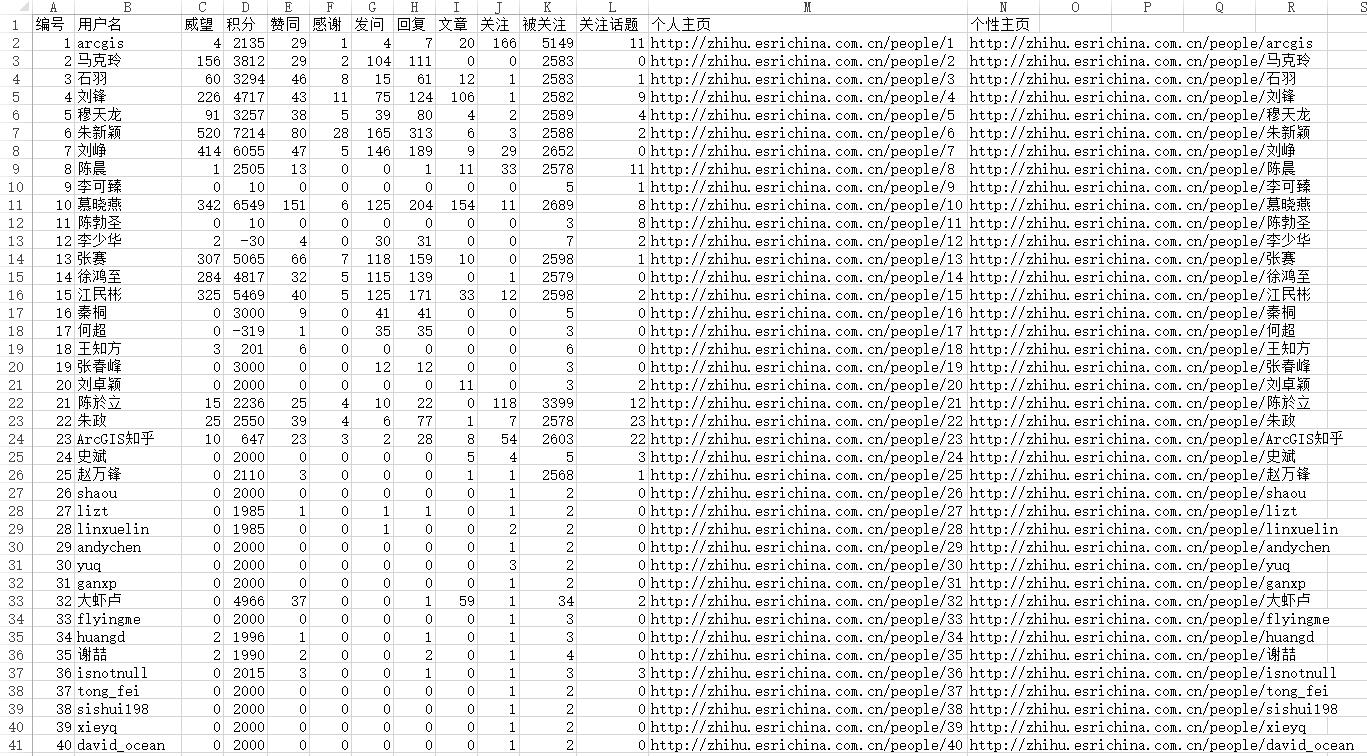
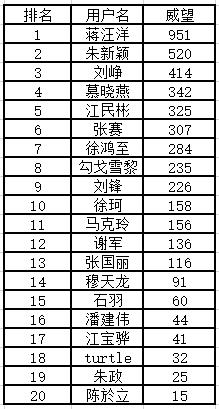
line ="编号"+ ',' + "用户名"+ ',' + "威望" + ',' + "积分" + ',' + "赞同" + ',' + "感谢" + ',' + "发问" + ',' + "回复" + ',' + "文章" + ',' + "关注" + ',' + "被关注" + ',' + "关注话题" + ',' +"个人主页" + ',' +"个性主页" + '\n'
file = file.write(line)
num=0
shuliang=input("请输入需要爬取的用户数量:")
for namecode in range(1,shuliang+1):
url = 'http://zhihu.esrichina.com.cn/people/' + str(namecode)
header = {'Host': 'zhihu.esrichina.com.cn','User-Agent': 'Mozilla/5.0 (Windows NT 6.1; rv:26.0) Gecko/20100101 Firefox/26.0','Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8','Connection': 'keep-alive'}
try:
req = urllib2.Request(url, headers = header)
con = urllib2.urlopen( req )
doc = con.read()
soup = BeautifulSoup.BeautifulSoup(doc)
user_name = soup.html.body.find('div', {'class': 'mod-head'}).h1
str123=str(user_name)
user_name1 = re.sub(r'\s|<h1>|<.*>', '', str123)
weiwang1 = soup.findAll('em', {'class': 'aw-text-color-green'})
chengjiu1=soup.findAll('em', {'class': 'aw-text-color-orange'})
q_a = soup.findAll('span', {'class': 'badge'})
fensi = soup.findAll('em', {'class': 'aw-text-color-blue'})
weiwang2=weiwang1[0:len(weiwang1) / 2]
chengjiu=chengjiu1[0:len(chengjiu1) / 2]
weiwang = re.sub(r'<em class="aw-text-color-green">|<.*>', '', str(weiwang2[0]))
jifen=re.sub(r'<em class="aw-text-color-orange">|<.*>', '', str(chengjiu[0]))
zantong = re.sub(r'<em class="aw-text-color-orange">|<.*>', '', str(chengjiu[1]))
ganxie = re.sub(r'<em class="aw-text-color-orange">|<.*>', '', str(chengjiu[2]))
fawen=re.sub(r'<span class="badge">|<.*>', '', str(q_a[0]))
huifu=re.sub(r'<span class="badge">|<.*>', '', str(q_a[1]))
wenzhang=re.sub(r'<span class="badge">|<.*>', '', str(q_a[2]))
guanzhu=re.sub(r'<em class="aw-text-color-blue">|<.*>', '', str(fensi[0]))
beiguanzhu = re.sub(r'<em class="aw-text-color-blue">|<.*>', '', str(fensi[1]))
guanzhuhuati = re.sub(r'\n|<em class="aw-text-color-blue">|<.*>', '', str(fensi[2]))
gerenzhuye='http://zhihu.esrichina.com.cn/people/'+str(namecode)
gexingzhuye='http://zhihu.esrichina.com.cn/people/'+user_name1
print "正在爬取用户【"+user_name1+"】的信息"
file = open('C://Users//Esri//Desktop//arcgiazhihu.txt', 'a')
line = str(namecode)+ ',' +str(user_name1)+ ',' + weiwang + ',' + jifen + ',' + zantong+ ',' + ganxie+ ',' + fawen+ ',' + huifu+ ',' + wenzhang+ ',' + guanzhu+ ',' + beiguanzhu+ ',' + guanzhuhuati +',' +gerenzhuye+',' +gexingzhuye+ '\n'
file = file.write(line)
num=num+1
except Exception, e:
print "用户"+str(namecode)+"不存在"
continue
endtime = datetime.datetime.now()
time = (endtime - starttime).seconds
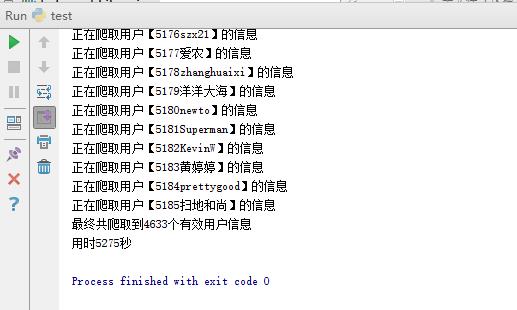
print "最终共爬取到"+str(num)+"个有效用户信息"
print "用时"+str(time)+"秒"
|