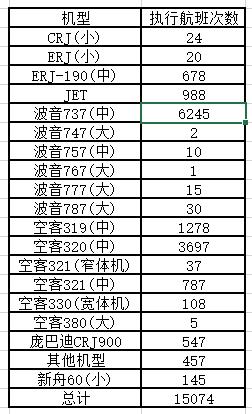
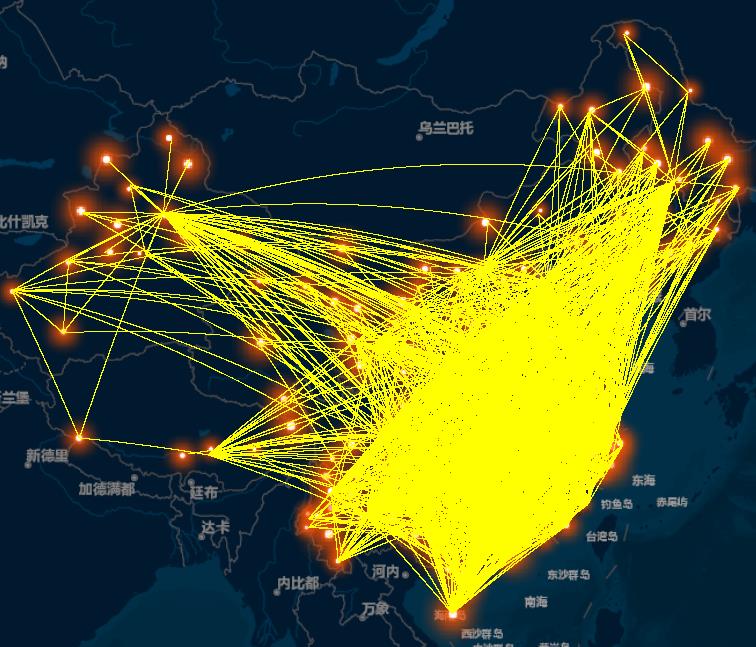
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
| import requests
from bs4 import BeautifulSoup
import re
from multiprocessing import Pool
import sys
reload(sys)
sys.setdefaultencoding('utf-8')
def geturl(url):
headers={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/45.0.2454.101 Safari/537.36'}
hbpage = requests.get(url, headers=headers).text
print hbpage
return hbpage
def flyin(city_citys,numm):
print '>>>>>进程%d开始>>>>>'%(numm+1)
pageinfo = []
for city_city in city_citys:
hbpage=geturl(city_city)
bg=str(city_city.split('=')[-2]).replace('&arrival','')
dg=city_city.split('=')[-1]
ft=(bg+dg)
print ft
if BeautifulSoup(hbpage, 'lxml').select('p[class="msg2"]'):
print '此线路无航班'
else:
hblc = BeautifulSoup(hbpage, 'lxml').select('em')[0].get_text()
print hblc
hbtitle=BeautifulSoup(hbpage,'lxml').select('span[class="title"]')
hbbc1=[]
hkgs1=[]
jixing1=[]
for ht in hbtitle:
hbbc=re.findall(r'\w.?\d*',ht.get_text())[0]
hkgs=ht.get_text().split(hbbc)[0]
jixing=ht.get_text().split(hbbc)[1]
hbbc1.append(hbbc)
hkgs1.append(hkgs)
jixing1.append(jixing)
hbtime=BeautifulSoup(hbpage,'lxml').select('span[class="c2"]')[1:]
qfsj1=[]
jlsj1=[]
for qj in hbtime:
qfsj=qj.get_text()[:5]
jlsj=qj.get_text()[5:]
qfsj1.append(qfsj)
jlsj1.append(jlsj)
hbjc=BeautifulSoup(hbpage,'lxml').select('span[class="c3"]')[1:]
qfjc1=[]
jljc1=[]
for jc in hbjc:
qfjc=jc.get_text().split('机场'.decode('utf-8'))[0]+'机场'.decode('utf-8')
jljc=jc.get_text().split('机场'.decode('utf-8'))[1]+'机场'.decode('utf-8')
qfjc1.append(qfjc)
jljc1.append(jljc)
zdl=BeautifulSoup(hbpage,'lxml').select('span[class="c4"]')[1:]
zdl1=[]
wdsj1=[]
for zd in zdl:
zdlv=zd.get_text().split('%')[0]+'%'
wdsj=zd.get_text().split('%')[1]
zdl1.append(zdlv)
wdsj1.append(wdsj)
bq=BeautifulSoup(hbpage,'lxml').select('span[class="c5"]')[1:]
duty1 = []
for xq in bq:
week=re.split('\">\d</span>',str(xq))[:-1]
week1=[]
ii=1
for day in week:
if ii==1:
dd='周一'
elif ii==2:
dd = '周二'
elif ii==3:
dd = '周三'
elif ii==4:
dd = '周四'
elif ii==5:
dd = '周五'
elif ii==6:
dd = '周六'
elif ii==7:
dd = '周日'
if day[-4:]=='blue':
duty='%s有班期'%dd
else:
duty='%s没有班期'%dd
ii+=1
week1.append(duty)
duty1.append(week1)
bqyxq = BeautifulSoup(hbpage, 'lxml').select('span[class="c7"]')[1:]
qs1=[]
js1=[]
for yxq in bqyxq:
yxs=yxq.get_text()[:10]
yxe=yxq.get_text()[:10]
qs1.append(yxs)
js1.append(yxe)
print hbbc1
for li in range(len(hbbc1)):
print '标记'
pageinfo.append(bg + ',' + dg + ',' + hblc + ',' + hbbc1[li] + ',' + hkgs1[li] + ',' + jixing1[li] + ',' + qfsj1[li] + ',' + jlsj1[li] + ',' + qfjc1[li] + ',' + jljc1[li] + ',' + zdl1[li] + ',' + wdsj1[li] + ',' + duty1[li][0] + ',' + duty1[li][1] + ',' + duty1[li][2] + ',' +duty1[li][3] + ',' + duty1[li][4] + ',' + duty1[li][5] + ',' + duty1[li][6] + ',' + qs1[li] + ',' + js1[li] + '\n')
print bg + ',' + dg + ',' + hblc + ',' + hbbc1[li] + ',' + hkgs1[li] + ',' + jixing1[li] + ',' + qfsj1[li] + ',' + jlsj1[li] + ',' + qfjc1[li] + ',' + jljc1[li] + ',' + zdl1[li] + ',' + wdsj1[li] + ',' + duty1[li][0] + ',' + duty1[li][1] + ',' + duty1[li][2] + ',' +duty1[li][3] + ',' + duty1[li][4] + ',' + duty1[li][5] + ',' + duty1[li][6] + ',' + qs1[li] + ',' + js1[li] + '\n'
print pageinfo
return pageinfo
def urlsplit(urls,jiange):
urli=[]
for newj in range(0,len(urls),jiange):
urli.append(urls[newj:newj+jiange])
return urli
if __name__=='__main__':
finalre=[]
files = open(r'C:\Users\username\Desktop\url.txt', 'r')
urls=[]
for url in files.read().split():
urls.append(url)
urlss=urls[:6]
urlll=urlsplit(urlss,2)
p = Pool(2)
result=[]
for i in range(len(urlll)):
result.append(p.apply_async(flyin,args=(urlll[i],i)))
p.close()
p.join()
print result
for result_i in range(len(result)):
print result[result_i]
fin_info_result_list = result[result_i].get().decode('utf-8')
finalre.extend(fin_info_result_list)
filers=open(r'C:\Users\username\Desktop\url55.txt','a+')
for fll in finalre:
filers.write(str(fll).encode('utf-8'))
|