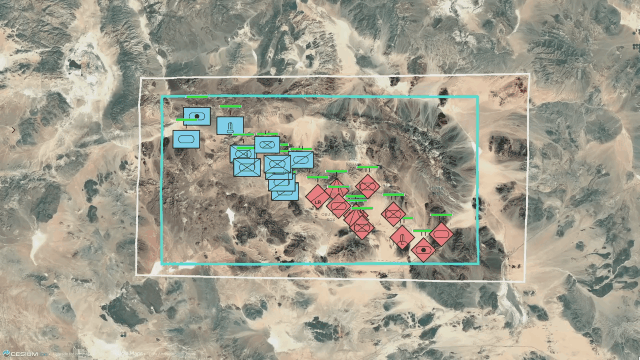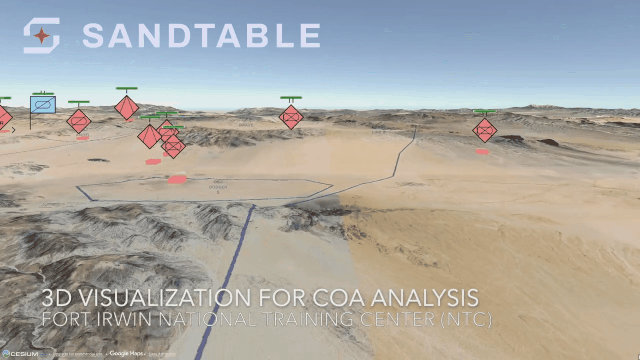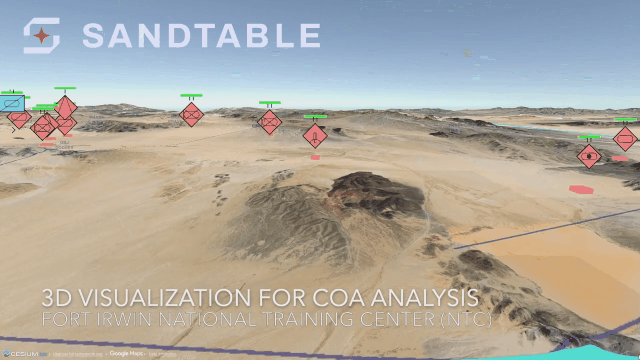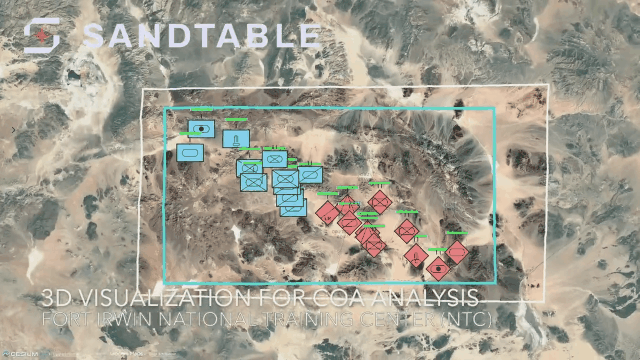
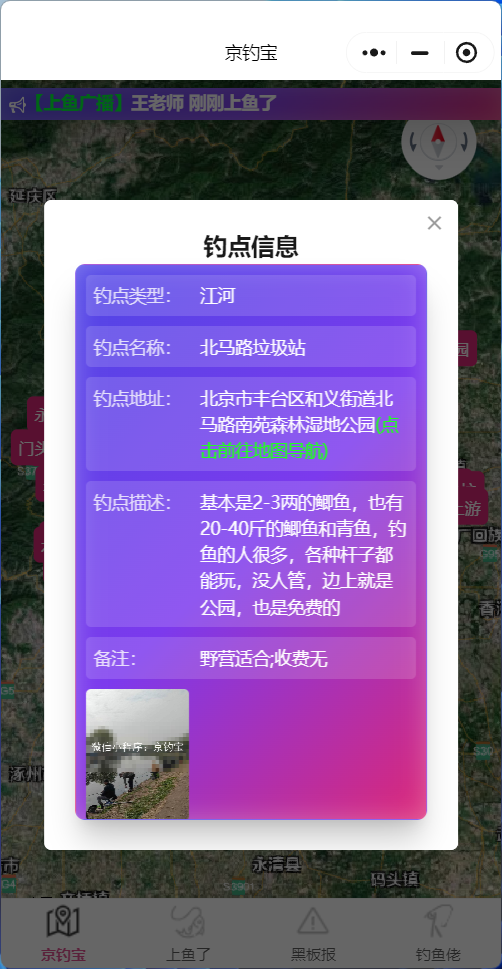
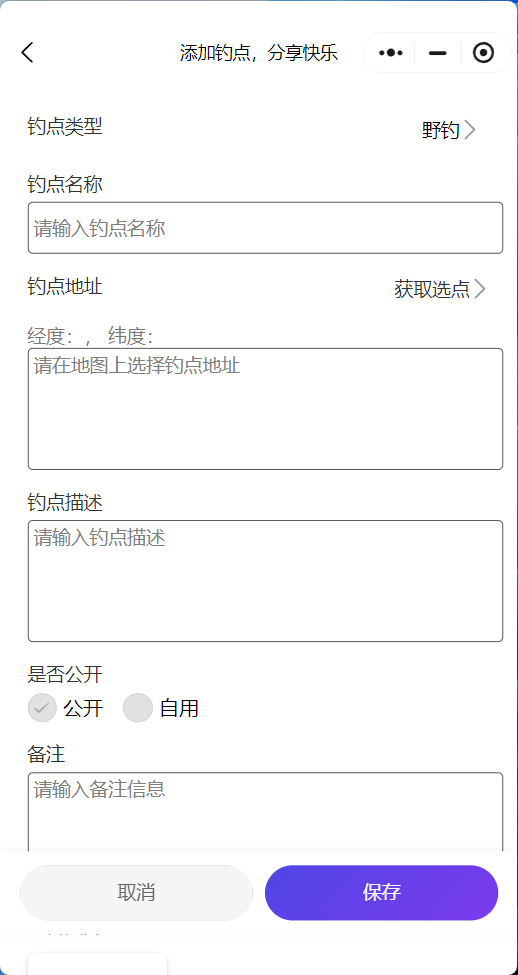
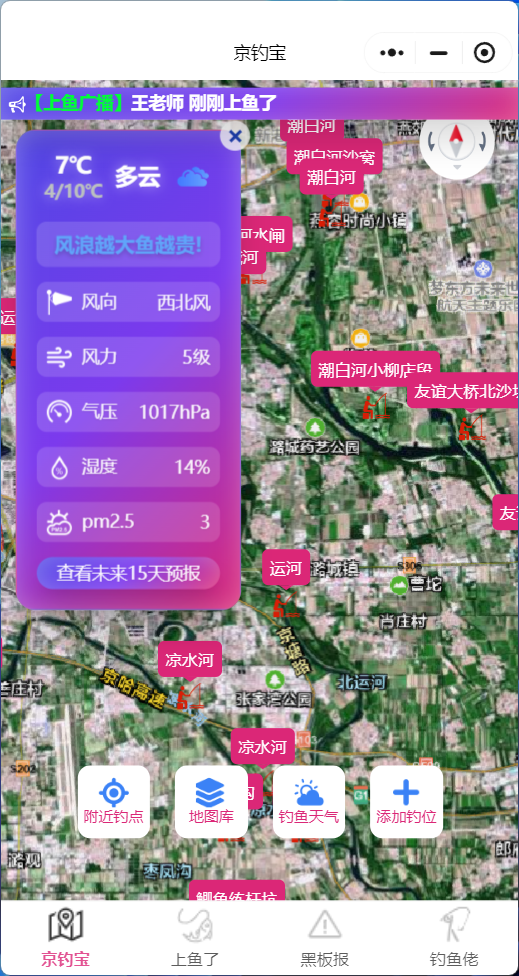
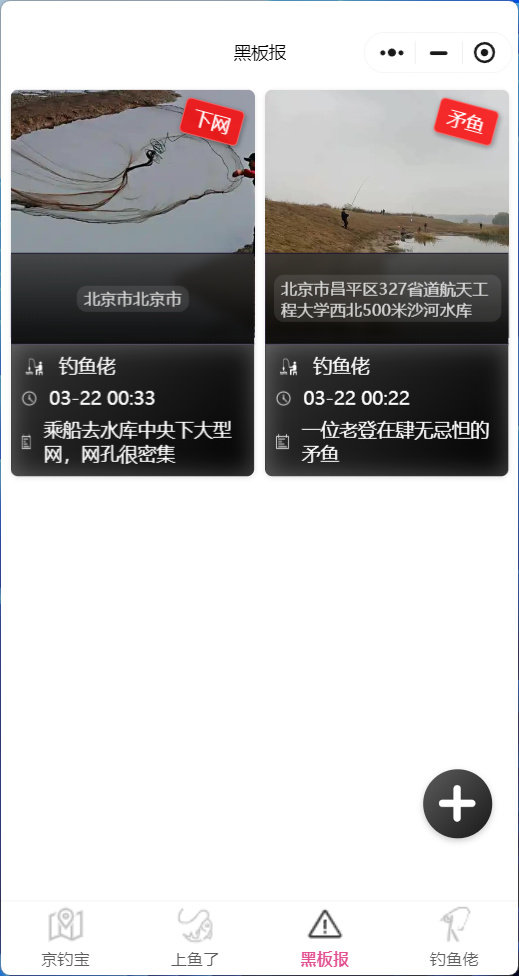
ERROR: template database 'template1' has a collation version mismatch DETAIL: The template database was created using collation version 2.36, but the operating system provides version 2.31. HINT: Rebuild all objects in the template database that use the default collation and run ALTER DATABASE template1 REFRESH COLLATION VERSION, or build PostgreSQL with the right library version.
这个错误表明,模板数据库 ‘template1’ 的排序规则版本(collation version 2.36)与操作系统提供的版本(2.31)不匹配,导致无法成功创建新数据库。